Gemini 3 Flash updates with Agentic Vision: here's how it works
Google introduces AI capable of actively analysing images

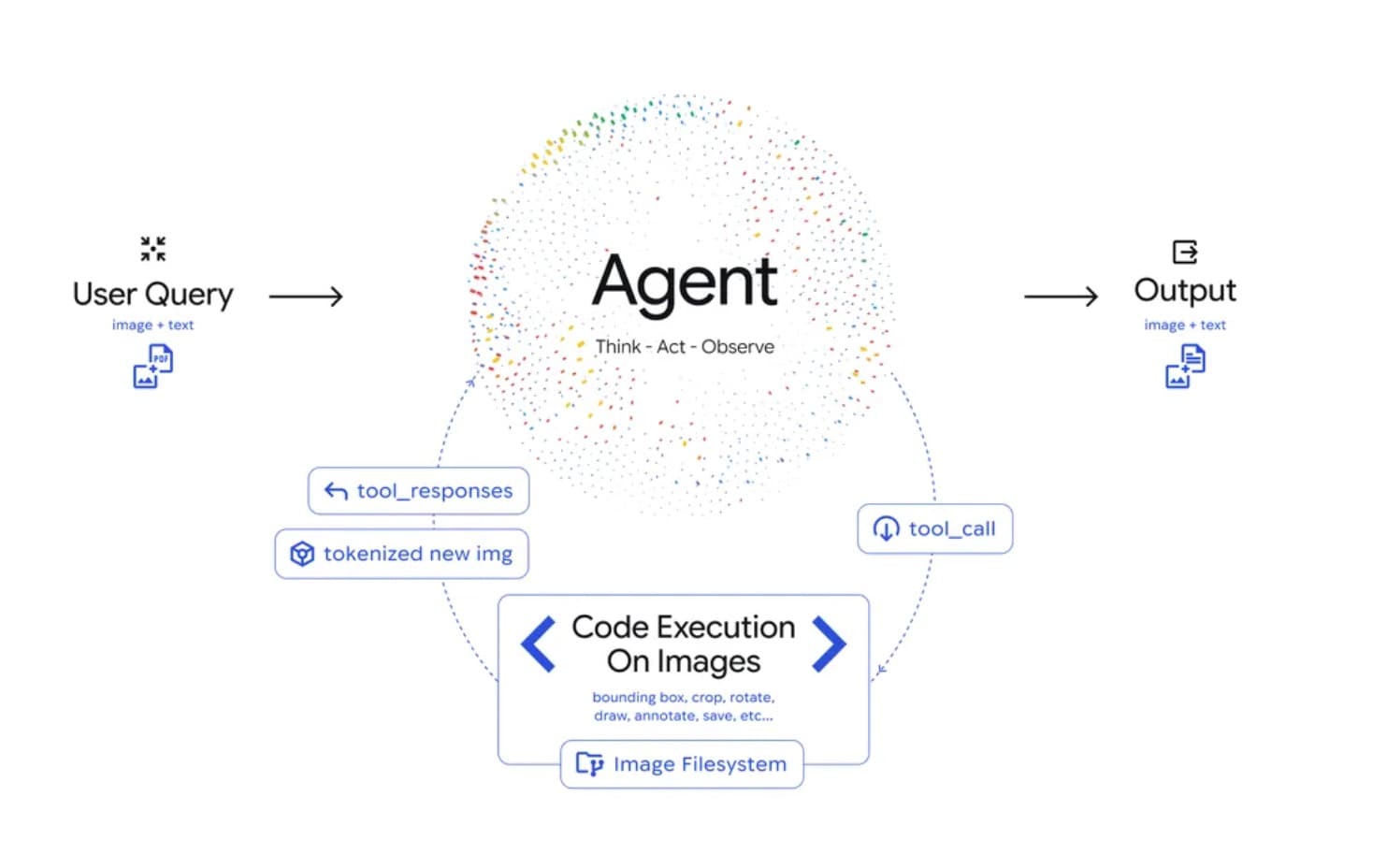
Agentic Vision can interpret the content of the images, formulate the code to make changes and provide more accurate answers
Despite being advanced, most artificial intelligence models capable of reading images perform a static scan by observing the input with a single glance; in fact, the loss of a less visible detail such as a road sign in the distance or a barely readable serial code of a microchip would force them to have to guess.
In this regard, Google has announced the debut of an important new feature in Gemini 3 Flash and christened it Agentic Vision, aimed at converting image comprehension into an agentic process involving reasoning so that the model can return more accurate feedback: the combination of visual reasoning with code execution, in fact, allows the model to generate plans to inspect, zoom in and manipulate images and provide answers based on visual evidence. In other words, the model provides a cycle consisting of three different phases: Think performs an analysis of the query and the initial image, Act executes Python code to actively intervene on the images with cropping, rotations, annotations and analysis, and finally, Observe adds the processed image to the model's context window to analyse it with data from a better context before generating a final answer.