
OpenAi Dev Day, everything you need to know
Four tools for developers announced. No new chatbots.

2' min read
2' min read
OpenAI at its developer event announced some new tools designed to simplify the creation of advanced AI apps. No new LLMs as expected, but tools that update existing functionalities. Four tools were presented, let's go in order. API Realtime enables low-latency multimodal experiences to be integrated into apps, with speech-to-speech conversations. Then a fine-tuning mode of GPT-4o with images and text is offered. This opens up new possibilities for visual search, object detection and biomedical image analysis. Prompt Caching reduces costs and latency by 50 per cent for developers. And Model Distillation Suite that helps create smaller, more efficient models, equalling the performance of larger models at a lower cost. Let's see how they work.
Realtime APIs for voice services.
It is designed for voice mode. Previously, to create a similar voice assistant experience, developers had to transcribe audio with an automatic speech recognition model such as Whisper, pass the text to a text model for inference or reasoning, and then play back the model's output using text to speech. According to OpenAi, thea Realtime API improves this process by directly transmitting audio input and output, enabling more natural conversational experiences. It can also automatically handle interruptions, just like the Advanced Voice mode in ChatGPT.
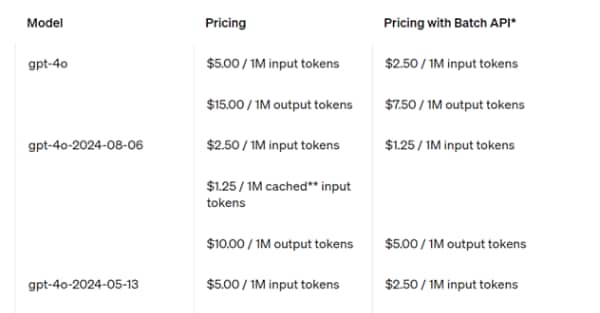
Fine Tuning Mode for Gpt-4o
.In practice, developers can optimise Gpt 4o with images and text. Let us see what changes for images. Visual fine-tuning follows a similar process as text fine-tuning: developers can prepare their image datasets so that they follow the correct format and then upload that dataset to our platform. According to OpenAi, developers can now improve the performance of GPT-4o for visual tasks with as few as 100 images and achieve even higher performance with larger volumes of text and image data.
Prompt Caching, automatic discounts on queries
.Automatic discounts are offered on inputs that the model has seen recently. Many developers, the site says, repeatedly use the same context on multiple API calls when creating AI applications, such as when making changes to a code base or having long multi-turn conversations with a chatbot. With Prompt Caching, they promise to reduce costs and latency. By reusing recently seen input tokens, developers can achieve a 50 per cent discount and faster prompt processing times.


