
Anthropic launches Claude Opus 4.5: Ai giants battle over code
New model tops benchmarks with half price and a challenge that redefines the boundaries of artificial intelligence

The war on artificial intelligence has a new battleground: autonomous programming. And this week saw a tight duel between two giants vying for technological supremacy. On the one hand Anthropic, with its Claude Opus 4.5 launched last Monday. On the other Google, which a few days earlier had introduced the Gemini 3, including the Pro model. A rivalry that is not just a matter of prestige, but is worth billions of dollars and redraws the balance of the tech sector.
Claude first for coding
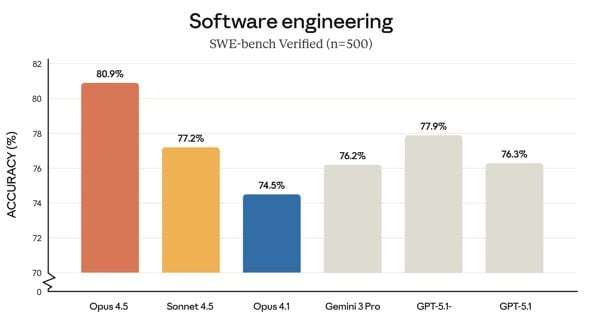
When it comes to AI models, benchmarks are the ultimate yardstick. And here the battle gets interesting. According to data published by the company, Claude Opus 4.5 scored 80.9 per cent on SWE-bench Verified, one of the most frequently cited tests to assess real-world problem-solving capabilities from GitHub repositories. A result that puts it ahead of all others: OpenAI's GPT-5.1-Codex-Max stops at 77.9 per cent, its predecessor Claude Sonnet 4.5 at 77.2 per cent, and Gemini 3 Pro - its direct rival - comes in at 76.2 per cent.
These differences may seem subtle, but in the world of AI, every percentage point counts. Especially when it comes to solving real software engineering problems. SWE-bench Verified analyses 500 authentic issues from GitHub repositories, problems that human developers have actually faced and solved. The ability of a model to understand the context, navigate a complex codebase and produce a working solution is the true test of practical intelligence.
But Anthropic does not limit itself
to claim the gold medal for coding. On OSWorld, the benchmark that measures the ability to use a computer as a human would, Claude Opus 4.5 scores 66.3 per cent, confirming it as the absolute best model for 'computer use' - the ability to navigate interfaces, click buttons, fill in forms as a human would.

